AI超算
1 人工智能超算及挑战
AI超算是超算应用行业类型之一。
数据驱动业务、人工智能辅助决策
AI负载带来算力挑战
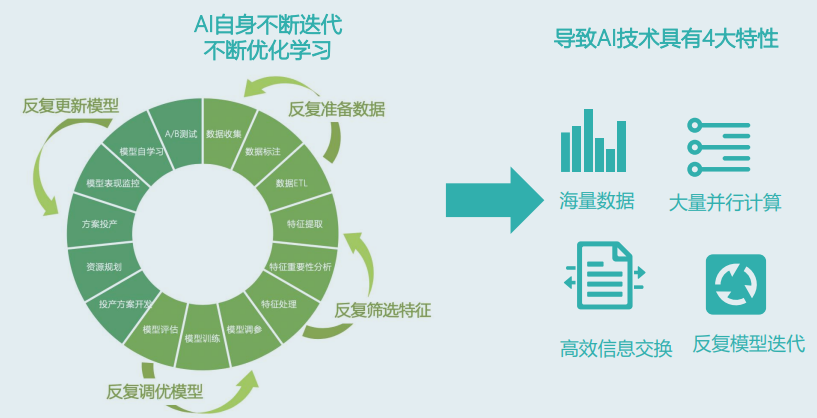
AI的全生命周期中有十几个流程环节,每个环节对计算、存储、网络、作业调度等方面的性能要求侧重点大为不同。
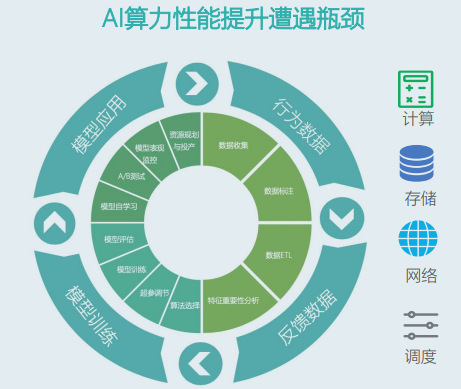
2 组网结构
算力由GPU/TPU/CPU异构方式组成。
与传统超算组网相比,存储架构上要复杂,如下
- AI数据源存储
位于超算外部,存储海量数据,可采用低成的对像存储系统hoodap。 - AI归档存储
位于超算外部,用于归档AI训练后的数据,可位于公网或私有存储网络。
AI超算存储架构示例
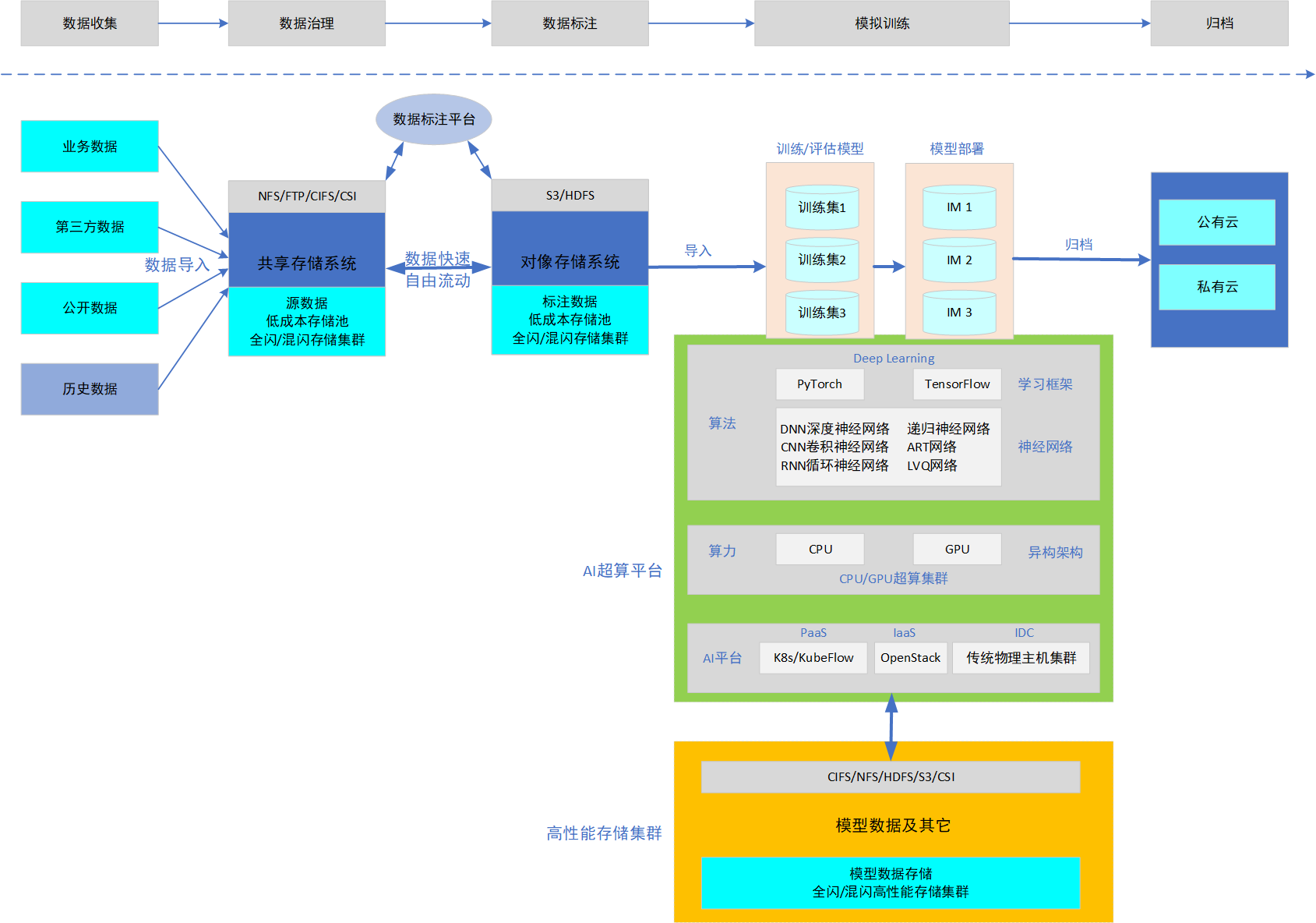
提示
从这个图看可以看��出,数据、算法、算力是AI超算的核心三要素。
3 神经网络模型、算法
神经网络模型
- DNN,深度神经网络(Deep Neural Network)
深度神经网络(DNN)是深度学习的基础,可以理解为有很多隐藏层的神经网络。 - CNN,卷积神经网络(Convolutional Neural Network) 卷积神经网络(CNN)是一种前馈型的神经网络,在大型图像处理方面有出色的表现,目前已经被大范围使用到图像分类、定位等领域中。
- RNN,循环神经网络(Recurrent Neural Network)
循环神经网络(RNN)是用于处理序列数据的神经网络,最大的不同之处就是在层之间的神经元之间也建立的权连接
其它网络模型
有多元感知器、玻尔兹曼机、递归神经网络等, 此外,还有自适应谐振理论(ART)网络、学习矢量量化(LVQ)网络、Kohonen网络、Hopfield网络等神经网络模型。
4 学习框架
深度学习训练和推理
| 项目 | 训练 | 推理 |
|---|---|---|
| 作用不同 | 训练是通过模拟人脑神经网络的学习过程,让计算机学会从大量数据中提取特征,并根据这些特征进行分类或预测,使计算机能够模拟人脑进行学习、记忆等操作; | 推理是根据已知信息,利用神经网络模型得出新的结论或预测。 |
| 阶段不同 | 训练是通过大量数据来训练模型,使模型能够更好地学习和理解数据; | 推理是在训练的基础上,通过给模型输入新的数据,得到相应的输出结果。 |
| 卡硬件要求不同 | 高算力、高显存、高带宽(如多机IB组网) | 对通讯带宽没有要求。 |
| 组网要求不同 | 单机多卡或多机多卡(AI超算集群) | 可单机单卡 |
提示
针对训练和推理不同目标,在选型英伟达GPU卡时要有所针对�性。
学习框架
| 学习框架 | 类型 | 简述 | 备注 |
|---|---|---|---|
| TensorFlow | 训练,推理 | Google开源的基于数据流图的机器学习框架,支持Python和C++程序开发语言。轰动一时的AlphaGo就是使用TensorFlow进行训练的,其命名基于工作原理,tensor 意为张量(即多维数组),flow 意为流动。即多维数组从数据流图一端流动到另一端。目前该框架支持Windows、Linux、Mac乃至移动手机端等多种平台 | |
| Caffe | 训练,推理 | 用于训练和运行神经网络模型的深度学习框架,视觉和学习中心可以对其进行开发。Caffe设计时充分考虑了表达、速度和模块化 | 单机多GPU方案 |
| Caffe-MPI | 训练,推理 | 用于训练和运行神经网络模型的深度学习框架,视觉和学习中心可以对其进行开发。 | 分布式集群扩展 |
| PyTorch | 训练 | 由Facebook人工智能研究小组开发,基于Lua编写的Torch库的Python实现的深度学习库,也是目前使用范围和体验感最好的一款深度学习框架。该框架主要用于人工智能领域的科学研究与应用开发,主要功能是拥有GPU张量,该张��量可以通过GPU加速,达到在短时间内处理大数据的要求,另外支持动态神经网络,可逐层对神经网络进行修改,并且神经网络具备自动求导的功能 | |
| MXNet | 训练 | 亚马逊维护的深度学习库,它拥有类似于 Theano 和 TensorFlow 的数据流图,为多 GPU 提供了良好的配置。MXNet结合了高性能、clean的代码,高级API访问和低级控制等优点 | |
| TensorRT | 推理 | 针对NVIDIA系列显卡具有其他框架都不具备的优势,如果运行在NVIDIA显卡上,TensorRT一般是所有框架中推理最快的。 | |
| ONNXRuntime | 推理 | 可以运行在多平台(Windows、Linux、Mac、Android、iOS)上的一款推理框架,它接受ONNX格式的模型输入,支持GPU和CPU的推理 | |
| OpenVINO | 推理 | Intel家出的针对Intel出品的CPU和GPU友好的一款推理框架,同时它也是对接不同训练框架如TensorFlow、Pytorch、Caffe等。 | |
| NCNN/MNN/TNN | 推理 | 针对手机端的部署 |