About HPC
1 什么是超算?
HPC是高性能计算(High Performance Computing)机群的简称,也即超级计算机(Super computer),是指能够执行一般个人电脑无法处理的大量资料与高速运算的电脑。

超算是以密集型实时计算为核心目的,使用大量处理器的单个计算机系统或者使用了多台计算机集群的计算系统和环境,多用于国家高科技领域和尖端技术研究。
超级计算机实际上是一个巨大的计算机系统,主要用来承担重大的科学研究、国防尖端技术和国民经济领域的大型计算课题及数据处理任务。如大范围天气预报,整理卫星照片,原子核物理的探索,研究洲际导弹、宇宙飞船等,制定国民经��济的发展计划,项目繁多,时间性强,要综合考虑各种各样的因素,依靠巨型计算机能较顺利地完成。
超算行业是国家重视的核心战略方向之一,是研究和应用人工智能必不可少的基础设施,是解决国家经济建设、社会发展、国防建设等领域重大挑战性问题的重要手段,已成为世界各国争夺的一个战略制高点
2 超算演变
2.1 超级计算机计算架构演变
由最初的向量机到目前用得最多的Cluster,运算效率发生质的变化,运算规模也增几何上涨。
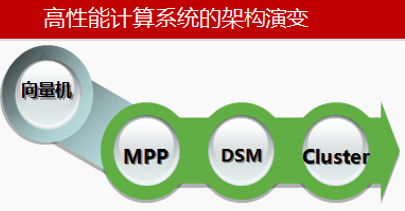
在cluster模式下的超算以网络为中心来提升如下能力
- 实时计算能力
- 大规模并行计算
- CPU/GPU异构计算,针对不同的计算对像采用不同的计算单元。
- 存储能力
- 大规模实时存储能力,提升存储I/O能力
- 任务调度能力
- 多任务大规模并行,任务间隔离。
- 硬件资源调度方面,所有计算力单元池化,硬件资源最小利用单位低到CPU核心、GPU cuda核心。
- 算法调度方面,多处类型的并行计算,计算任务管理颗粒度低到程序进程本身。
2.2 超级计算机计算单元演变
2007年以前,高性能计算都是CPU的天下,Intel和AMD寡头垄断。
2007年,Nvidia正式推出GPU加速器,杀入HPC市场。
2016年,Google推出针对AI行业的专业用卡TPU(Tersor Processing Unit)
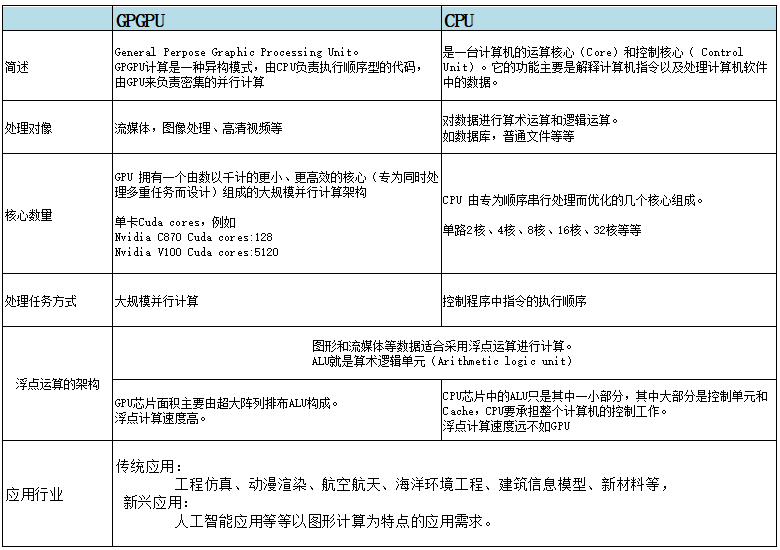
GPGPU/TPU计算是一种异构模式,由CPU负责执行顺序型的代码,由GPU/TPU来负责密集的并行计算,其浮点运算能力远超CPU。人工智能的概念60年前就已提出,但发展一直很缓慢,缺少强劲的计算能力支撑,有了GPU/TPU 后,人工智能将会飞跃发展。
从下图可以看出GPU与CPU的工作方式差异
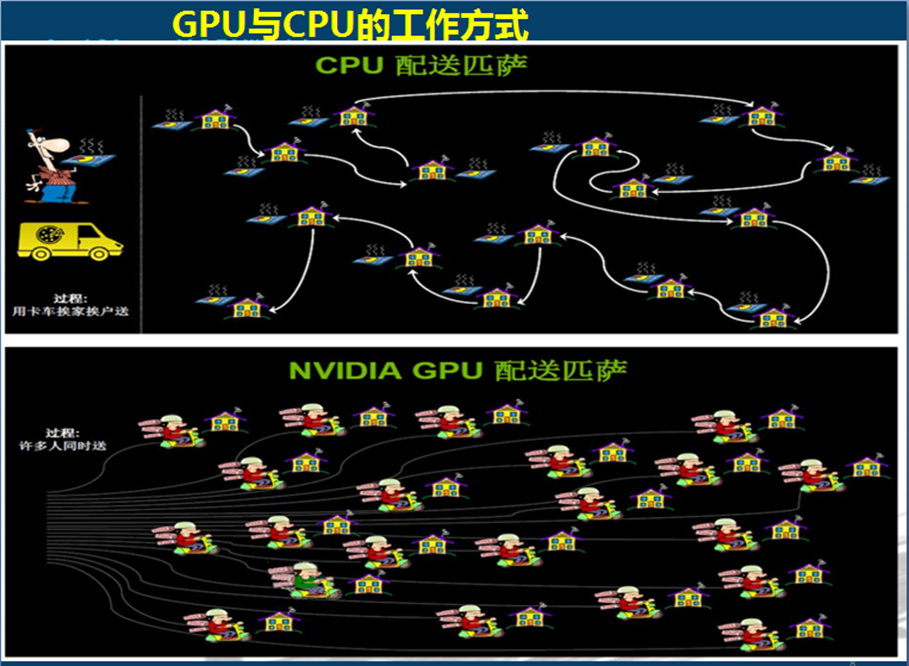
CPU是依次序先后来派送匹萨,GPU是以一定的规则来分组或一次性全部派送匹萨。 因此针对图形、视频的等深度学习领域的应用,GPU的速度远高于CPU。
3 超算应用领域
-
传统应用
工程仿真、动漫渲染、航空航天、海洋环境工程、建筑信息模型、新材料等.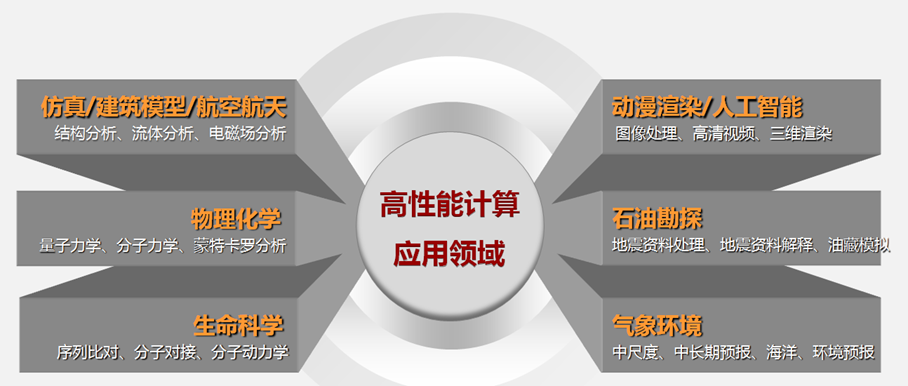
-
新兴应用
人工智能应用等等以图形、视频等为计算对像的应用需求,在今后将会几何增长。
4 超算架构
4.1 高性能计算系统组成
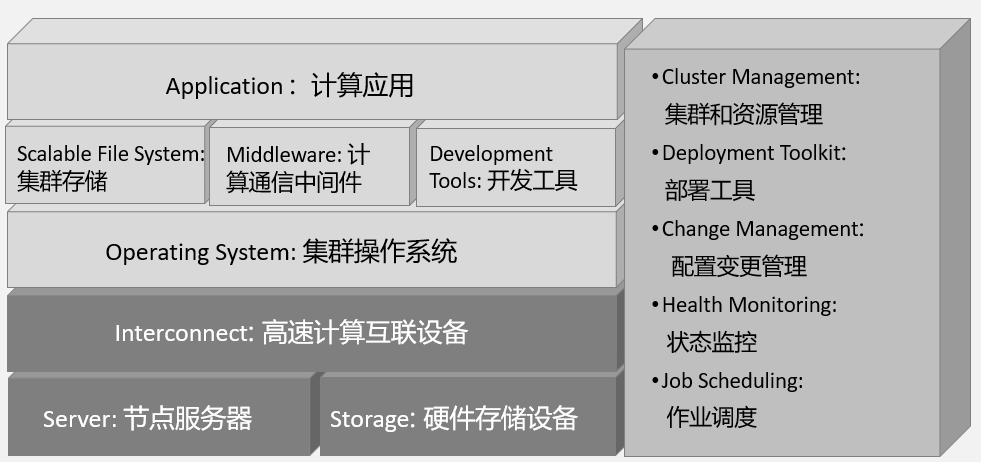
依照不同的行业,安装和部署相应的应用软件和库,核心包括如下几方面
- 作业调度,如:
- LSF Platform任务调度平台,颗粒度可以是计算单元的CPU核心、GPU cuda核心。
- Hyper Schedule任务调度平台,为人工智能作业调度。
- 算法调度,如
- MPI调度,颗粒度可以是进程本身。
- 多种类型的并行计算任务。
- 运算过程checkpoint,单点故障后续算。
4.2 典型组网拓扑
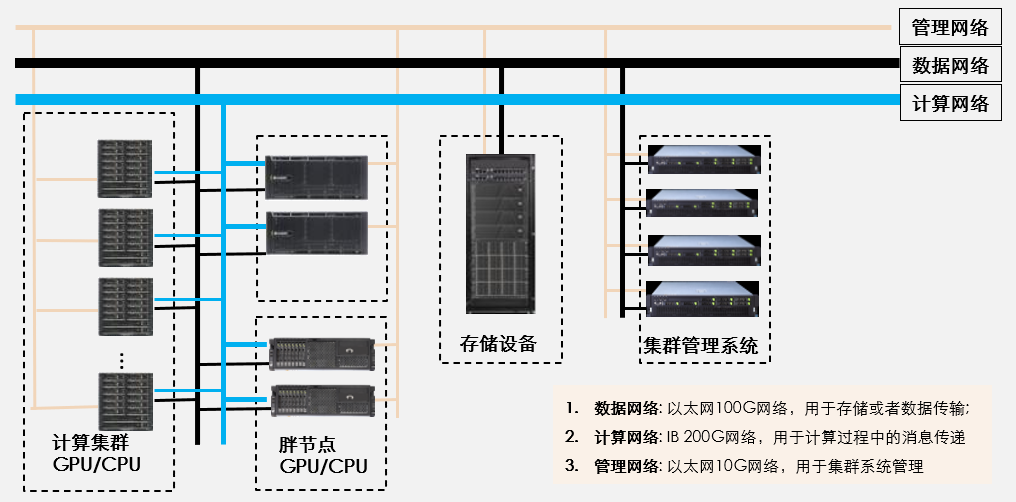
算力由GPU/TPU/CPU异构方式组成。
依据数据业务类型对网络进行划分类
- 计算网络:采用IB组网,低延时、高带宽。
- 数据网络:即高性能存储网络,分布式存储时可以采用IB组网,也可采用以太网。部分业务数据可采用FC-SAN方式。
- 业务网络:超算用户网络,采用以太网。采用ssh、web、或跳板机节点等方式接入。
- 管理网络:超算管理员所在网络,采用以太网。
- 运维网络:超算硬件管理和监控网络,运维人员所在网络,采用以太网。
5 云计算、超算、大数据 三者区别
| 项目 | 云计算(IaaS为例) | HPC超算 | 大数据 |
|---|---|---|---|
| 背景不同 | 虚拟技术的发展推动了云计算,各类资源(CPU/GPU/内存等算力、存储、网络等)池化 | 大模型对算力的高需求,推动集群化并行算力发展 | 用户和社会各行各业所产生大的数据呈现几何倍数的增长,需从中分析出有价值的信息 |
| 核心价值不同 | 节约IT使用成本,IT资源利益最大化 | 快速实时计算,模型推演 | 从海量信息中挖掘有价值的信息 |
| 处理对�像不同 | 资源池化,按需组成新计算系统(含完整的模块,CPU/RAM/HD/IO/Network),实现资源调度 | 集群的算力并行化(非池化),快速计算,对模型进行推演 | 数据的处理和分析,包括数据的采集、存储、处理、分析和展示等 |
| 需向用户不同 | 对IT资源有需求的普通企业或个人用户 | 大型企业自身、研究机构等 | 大型B/G客户 |
| 集成要求不同 | 低 | 高 | 低 |
| 架构层级不同 | 基础架构资源层 | 应用层 | 应用层 |
6 超算机构列举
- Frontier
TOP500中排名第一的系统,由美国能源部运营,使用8,699,904个内核实现了1.194Exaflop/s,是HPE Cray EX架构结合了针对HPC和AI优化的第三代AMD EPYC CPU、AMD Instinct 250X加速器和Slingshot-11互连。 - 神威·太湖之光
由国家并行计算机工程技术研究中心研制,坐落在江苏省无锡市国家超级计算中心,理论峰值性能为125.4Pflop/s,实际最大算力为93Pflop/s,在2022年的榜单上排名第四 - 天河二号
由国防科技大学研制,部署在广州国家超级计算机中心,理论峰值性能为100.7Pflop/s,实际最大算力为61.4Pflop/s,在2022年的榜单上排名第七 - 深圳国家超级计算中心
2009年获批成立。二期2022年11月14日,深圳国家超级计算中心二期项目在光明科学城大科学装置区开工,该项目是科技部和深圳共同布局的重大创新基础设施,将建成新一代E级超级计算机,实现大规模科学计算、工业计算、专业大数据处理及智能超算创新服务 - 鹏城云脑
鹏城实验室研发的智算平台,算力达100P的AI技术试验平台"鹏城云脑I"已建成,大规模AI算力平台"鹏城云脑II"正在建设中,下一代融合智能超级算力平台"鹏城云脑III"已在国家发改委完成立项答辩。